話題のStable DiffusionをIvy Bridge+GTX1050Tiで試す
最近話題となっている画像生成AI、「Stable Diffusion」。
2022年9月2日時点では、オープンソースかつ無償で利用でき、画像の権利は生成者にあるとされており、汎用性が高いことから話題になっています。
今回は、そんなStable Diffusionをそこまでハイスペックではないマシンで動かすことができるのか、検証してみました。
前提環境
今回検証した環境は、下記のとおりです。
- CPU: Intel(R) Core(TM) i5-3470 CPU @ 3.20GHz
- GPU: NVIDIA GeForce GTX 1050 Ti
- RAM: DDR3 8GB
- OS: Ubuntu 20.04.5 LTS
1050Ti を搭載しているものの、全体的に2022年となってはハイスペックとは言えない環境構成となっています。
ソフトウェア環境
今回は、Python 3.8.10がプリインストール済み、CUDAセットアップも完了している状態で進めていきます。GeForceのドライババージョンは515.65.01、CUDA11.3で構築されています。GeForceドライバやCUDAの設定については別途調べてみてください、、、(別件でCUDA環境構築済みだったのでステップいちいち覚えてなかった)
また、IDEとしてPyCharm Community Editionを使用していますが、venvが構築できてエディタがあれば特にIDEは必要ないかと思います。(基本的にコマンドを叩いていくだけなので)
実践
今回は下記のURLを参考にさせていただき、構築を進めさせていただきます。
https://touch-sp.hatenablog.com/entry/2022/08/23/222916
はじめに、よしなに venv 環境を作成しておきます。(PyCharmでプロジェクトを作成)
続いて、pipで必要なモジュール類をダウンロードした後、stable-diffusionの軽量化されたフォーク版を git clone で手元に用意します。
(venv)$ pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
(venv)$ pip install -r https://raw.githubusercontent.com/dai-ichiro/env4stable-diffusion/main/requirements4py39.txt
(venv)$ git clone https://github.com/basujindal/stable-diffusion.git準備が完了したら、modelのckptデータをhuggingfaceから入手します。具体的には https://huggingface.co/CompVis/stable-diffusion-v-1-4-original から sd-v1-4.ckpt をダウンロードし、stable-diffusion/models/ldm/stable-diffusion-v1/model.ckptに配置します。
モデルチェックポイントデータの配置が完了したら、いよいよ実行です。
はじめに、軽量化されていない通常版で実行してみました。
(venv)$ python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms --ckpt models/ldm/stable-diffusion-v1/model.ckpt --n_samples 1結果は…メモリ不足で強制終了してしまいました。
今回使用したシステムはRAMが8GB、スワップ領域も8GBで組んでいたので、流石に足りなかったようです。
ということで、一旦スワップを増やしてゴリ押しで解決を試みます。
$ sudo fallocate -l 64G /swapfile
$ sudo chmod 600 /swapfile
$ sudo mkswap /swapfile
スワップ空間バージョン 1 を設定します。サイズ = 64 GiB (68719472640 バイト)
ラベルはありません, UUID=******
$ sudo swapon /swapfile
$ sudo swapon --show
NAME TYPE SIZE USED PRIO
/dev/sda6 partition 8G 0B -2
/swapfile file 64G 0B -3
$ free -h
total used free shared buff/cache available
Mem: 7.6Gi 1.7Gi 4.8Gi 99Mi 1.2Gi 5.6Gi
Swap: 71Gi 0B 71Gi本来はあまり SSD 上にスワップ領域を確保するのは良くないのですが、、、その場しのぎでとりあえず実行してみました。
再び先程の通常版を実行してみると…今度は VRAM 容量が足りない旨のエラーが。
流石に GTX1050Ti の 4GB VRAM では少々足りなかったようです。
ということで、軽量版のコマンドを実行してみます。
(venv)$ python optimizedSD/optimized_txt2img.py --prompt "a photograph of an astronaut riding a horse" --H 512 --W 512 --seed 42 --n_iter 2 --n_samples 10 --ddim_steps 50時間は20分ほどかかりましたが…無事に動作させることができました!🎉
※module optimizedSD not found的なエラーが出た場合は、optimized_txt2img.pyの冒頭の方に下記の設定を追加することで動作するようになると思います。
import sys
sys.path.append("[optimizedSD/ があるディレクトリへのフルパス]")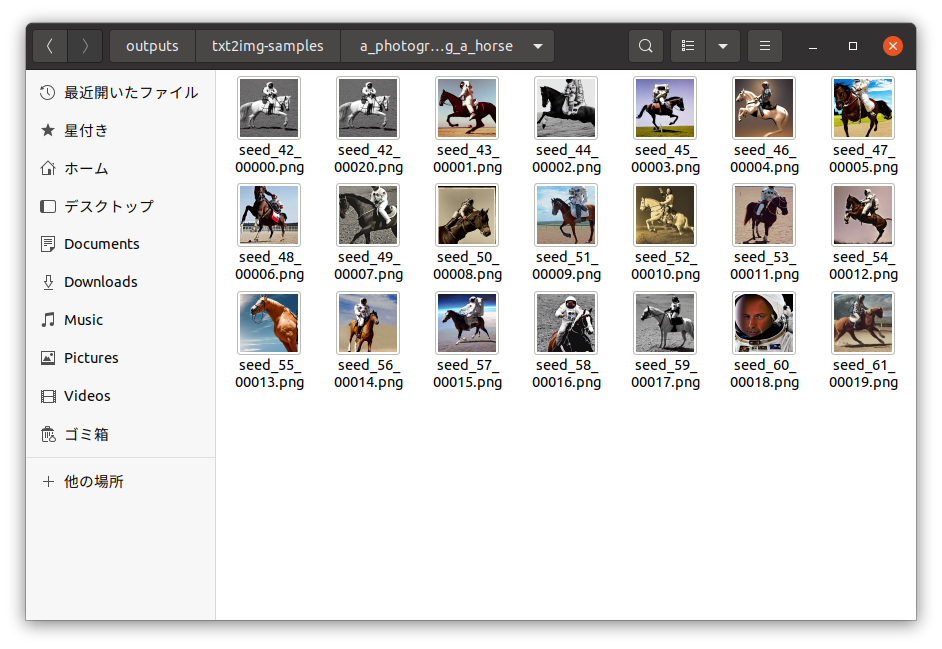
生成するためのいわゆる「呪文」は、--prompt に続く文章を変更することで対応可能です。
また、--n_iter を1に設定することでループ回数を1回に減らし、--n_samples で指定する生成枚数を減らすことで、一回の生成作業にかかる時間を抑えることができるようになります。
パフォーマンス
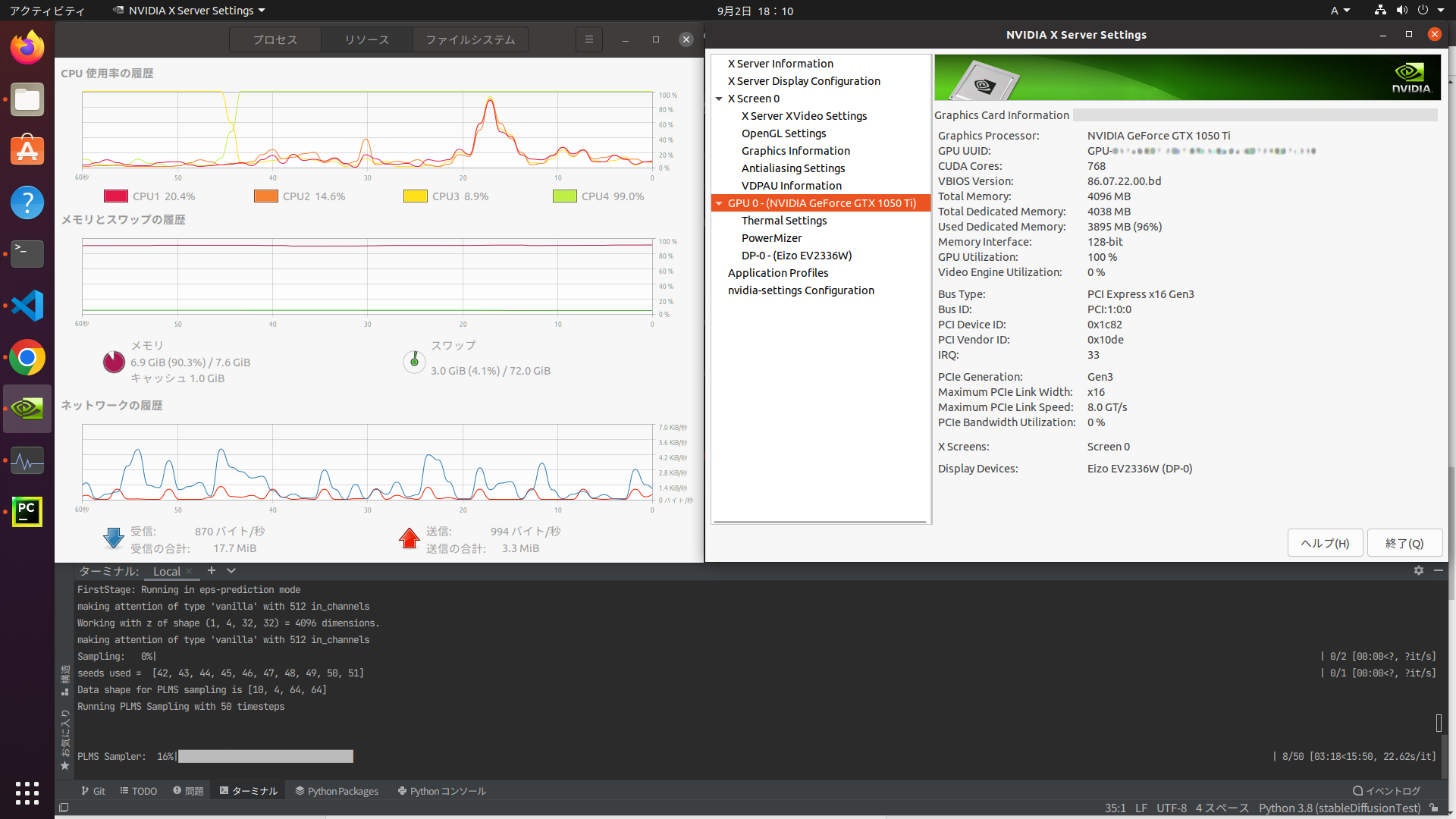
ちなみに、今回の環境構成ではCPUの1コアが使用率100%に張り付き、GPU使用率も生成が始まってからは100%に張り付いていました。(それぞれシステムモニター、NVIDIA X Server Settingsで確認)
また、RAM (+スワップ領域) はピーク時で 18GB ほど使用されていました。16GBメモリ搭載機であれば、スワップの拡張作業などは必要なさそうです。
まとめ
ということで、タイトルにある通り Ivy Bridge 世代のCPUと GeForce GTX1050Ti を使用して、Stable Diffusion を使用した画像生成を行ってきました。
最新環境と比較すると時間はかかるものの、工夫すればこの世代のマシンたちでも動作する汎用性の高さに素直に驚いています。
いろいろと話題の尽きない画像生成AI界隈ですが、引き続きウォッチしていければ良いなと思う次第です。